

I‘ve worked with the Nuxeo content service platform for a few months and i need now to populate this platform within XX Million assets.
All systems i already work with handle this “problem” with a solution like ETL or Big Batch to use a mechanism like :
- Prepare all your data
- Unplug all your system engines (index, automation etc…)
- Inject your data (but be careful with all linked or nested data)
- Restart system and monitor e ach service as it starts (service after service)
- And then validate all the content here
- I need to see and verify quickly
- I need to define the approach wit a repeatable configuration - i can also easily share with team
- I want to test my docker or whatever environment before production
The challenge with this approach is that Nuxeo should ingest all those 60 Millions assets. I trust the Nuxeo Benchmarks with numbers like +-1000 docs / sec that means 60M/1000sec -> 24h, less than a week end ? … looks good to me, so let’s go!
First, Environments
A real Nuxeo environment is complex - for a good reason : performance !
 VS
VS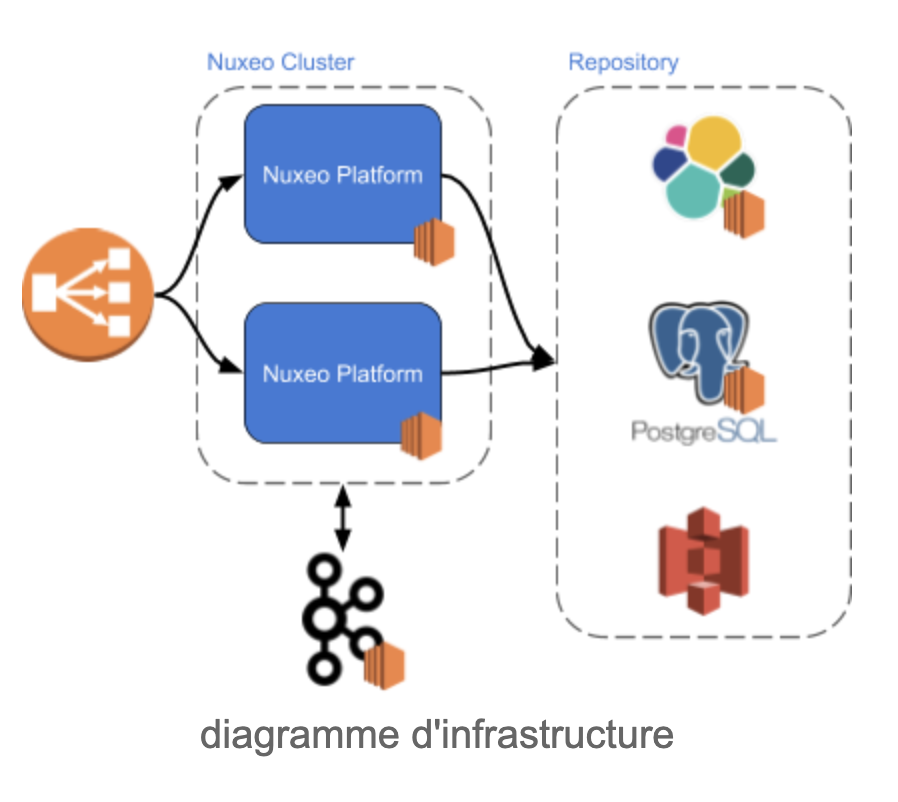
Second, Ingest client
Two client utilities could do the job, using respectively nuxeo java and nuxeo js client (and behind nuxeo rest api):- Nuxeo JHype, a spring / angularjs app that launch your scenario
- Nuxeo Tasks , a useful task launcher using gulp
I finally use the Nuxeo Tasks :

But at the end, job done (> 660 docs / sec). Cool !
Context
|
REST Api
|
Parallel REST Api (spring batch, or node)
|
A) Simple Nuxeo Docker.
|
4 docs/sec
|
-
|
8 docs/sec
|
-
| |
C) Full Nuxeo Docker Cluster.
|
16 docs/sec
|
33 docs/sec
|
D) Real AWS Nuxeo Cluster - after problems solving.
|
330 docs/sec
|
660 docs/sec 😄
|

Third, Problems
The real problems came in the real environments.One problem you should take care is making sure that your client is well sized regarding your server. It means that you should scale the number of parallel HTTP connections regarding Nuxeo Connection Pool. Very simple to see and manage : look at the Nuxeo CPU. Nuxeo is under 70% for me with a client like 5 parallel ingestion tasks.
With that you can multiply by 2 your ingest capacity. Why not 5 ? Because we’ve got another bottleneck like database, and Nuxeo start using asynchronous treatments in Kafka. I want to finish the client job first, so that’s ok for me; Nuxeo will work for me during the night.
One other problem, is that feeding lots of data means some admin async process could struggle. It was the case for me on Nuxeo Orphan cleanup. Resolved by config (setting disabled like explained here).
The last one was linked to my Postgres DB and its config in Nuxeo - i know that something like MongoDB would be a better choice, but i need Postgres here -. Nuxeo Audit default config for Postgres is to be in database … and Nuxeo is auditing lots of things ! To resolve this problem you need to set Elasticsearch as audit repository.

Conclusion
In conclusion, i have been happy to see and test the awesome Nuxeo Platform.I finally succeed with my goal and learn with those tests, and I know now that:
- I can be confident on Nuxeo core (all my test leave the JVM without any fullgc)
- I set here a small AWS EC2 set, but you can scale up in lots of different ways
- You can go further but you need then to design all nodes beside (elasticsearch, database)... Nuxeo did a benchmark with Billions of assets ?! Or TeraOctet assets ?! Awesome, i have to say that to my wife :)